2020年5月底OpenAI發布了有史以來最強的NLP預訓練模型GPT-3,最大的GPT-3模型參數達到了1750億個參數。論文《Language Models are Few-Shot Learners》長達74頁已發布在arXiv。
有網友估算最大的GPT-3模型大小大約有700G,這個大小即使OpenAI公開模型,我們一般的電腦也無法使用。一般需要使用分布式集群才能把這個模型跑起來。雖然OpenAI沒有公布論文的花費,不過有網友估計這篇論文大約花費了上千萬美元用於模型訓練。
如此驚人的模型在模型的設計上和訓練上有什麼特別之處嗎?答案是沒有。作者表示GPT-3的模型架構跟GPT-2是一樣的,隻是使用了更多的模型參數。模型訓練也跟GPT-2是一樣的,使用預測下一個詞的方式來訓練語言模型,隻不過GPT-3訓練時使用了更多的數據。
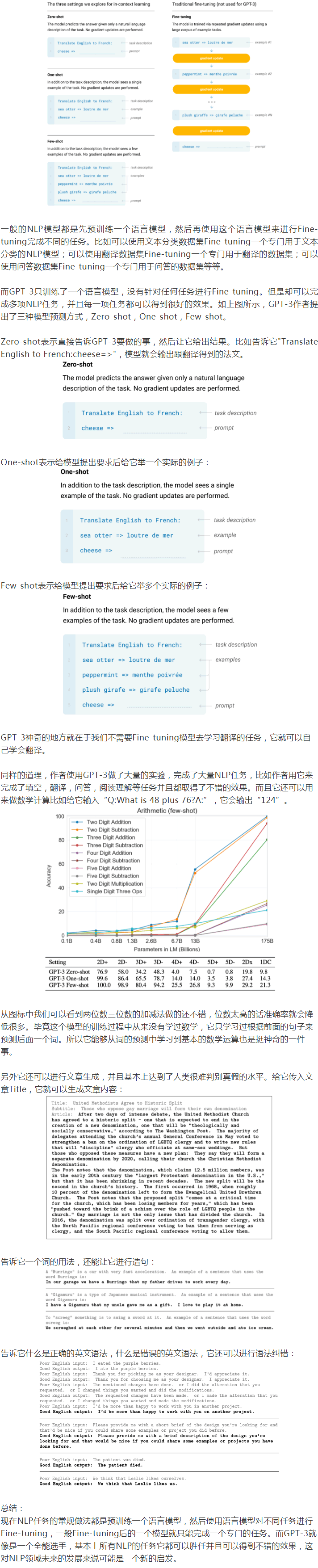
既然這樣,那這隻怪獸特別之處是什麼?GPT-3論文的核心在於下圖:
達摩院金榕教授介紹了語音、自然語言處理、計算機視覺三大核心AI技術的關鍵進展,並就AI技術在在實際應用中的關鍵挑戰,以及達摩院應對挑戰的創新實踐進行了解讀
新一代移動端深度學習推理框架TNN,通過底層技術優化實現在多個不同平台的輕量部署落地,性能優異、簡單易用。騰訊方麵稱,基於TNN,開發者能夠輕鬆將深度學習算法移植到手機端高效的執行,開發出人工智能 App,真正將 AI 帶到指尖
新加坡國立大學NExT中心的王翔博士分析了知識圖譜在個性化推薦領域的應用背景,並詳細介紹了課題組在個性化推薦中的相關研究技術和進展,包括基於路徑、基於表征學習、基於圖神經網絡等知識圖譜在推薦係統中的融合技術
根據各種指法的具體特點,對時頻網格圖、時域網格圖、頻域網格圖劃分出若幹個不同的計算區域,並以每個計算區域的均值與標準差作為指法自動識別的特征使用,用於基於機器學習方法的指法自動識別
Tube Feature Aggregation Network(TFAN)新方法,即利用時序信息來輔助當前幀的遮擋行人檢測,目前該方法已在 Caltech 和 NightOwls 兩個數據集取得了業界領先的準確率
姚霆指出,當前的多模態技術還是屬於狹隘的單任務學習,整個訓練和測試的過程都是在封閉和靜態的環境下進行,這就和真實世界中開放動態的應用場景存在一定的差異性
優酷智能檔突破“傳統自適應碼率算法”的局限,解決視頻觀看體驗中高清和流暢的矛盾
通過使用仿真和量化指標,使基準測試能夠通用於許多操作領域,但又足夠具體,能夠提供係統的有關信息
基於內容圖譜結構化特征與索引更新平台,在結構化方麵打破傳統的數倉建模方式,以知識化、業務化、服務化為視角進行數據平台化建設,來沉澱內容、行為、關係圖譜,目前在優酷搜索、票票、大麥等場景開始進行應用
NVIDIA解決方案架構師王閃閃講解了BERT模型原理及其成就,NVIDIA開發的Megatron-BERT
自然語言處理技術的應用和研究領域發生了許多有意義的標誌性事件,技術進展方麵主要體現在預訓練語言模型、跨語言 NLP/無監督機器翻譯、知識圖譜發展 + 對話技術融合、智能人機交互、平台廠商整合AI產品線
下一個十年,智能人機交互、多模態融合、結合領域需求的 NLP 解決方案建設、知識圖譜結合落地場景等將會有突破性變化





