
| 創澤機器人 |
| CHUANGZE ROBOT |
人機對話一直是自然語言處理領域內的重要研究方向之一,近年來隨著人機交互技術的進步,對話係統正逐漸走向實際應用。其中,智能客服係統受到了很多企業尤其是中大型企業的廣泛關注。智能客服係統旨在解決傳統客服模式需要大量人力的狀況,在節約人力的同時,使得人工客服在針對特別問題或者特別用戶時能夠提供更高質量的服務,從而實現“智能客服 + 人工客服”在服務效率和服務質量兩個維度上的整體提升。近年來,許多中大型公司都已經構建了自己的智能客服體係,例如富士通的 FRAP、京東的 JIMI 和阿裏巴巴的 AliMe 等。
智能客服係統的構建需要依托於行業數據背景,並基於海量知識處理和自然語言理解等相關技術。初代智能客服係統主要麵對業務內容,針對高頻的業務問題進行回複解決,此過程依賴於業務專家對高頻業務問題答案的準確整理,主要的技術點在於精準的用戶問題和知識點之間的文本匹配能力。新型的智能客服係統將服務範圍定義為泛業務場景,除了解決處理核心的高頻業務問題,智能導購能力、障礙預測能力、智能語聊能力、生活助理功能以及生活娛樂交互等方麵的需求也同樣被重視和涵蓋。其中,情感能力做為類人能力的重要體現,已經在智能客服係統的各個維度的場景中被實際應用,並且對係統類人能力的提升起到了至關重要的作用。
一 智能客服係統中情感分析技術架構
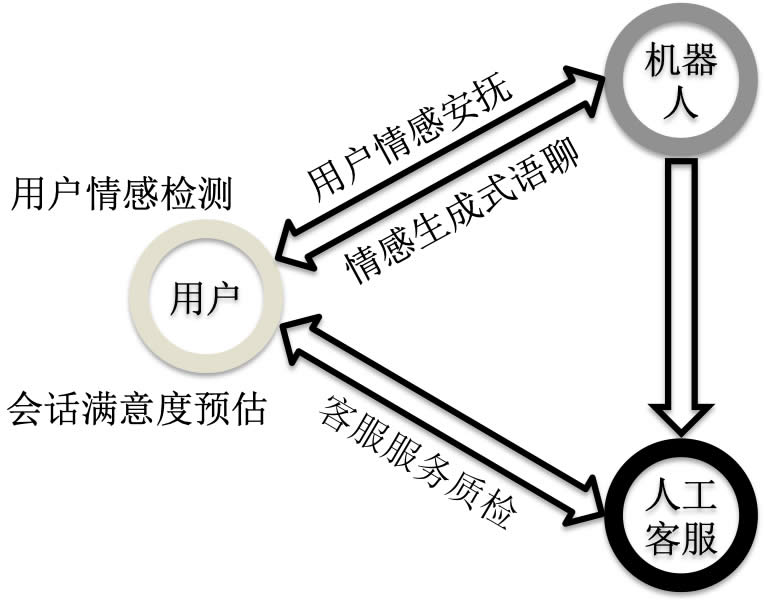
圖 1:智能客服係統中的情感分析技術架構
圖 1 給出了經典的人機結合的智能客服模式,用戶能夠通過對話的方式,接受來自機器人或者人工客服的服務,並且在接受機器人服務的過程中,能夠利用指令的方式或者機器人自動識別的方式跳轉到人工客服。在上述的完整客服模式中,情感分析技術已經被實際應用在多個維度的能力之上。
二 用戶情感檢測
1 用戶情感檢測模型介紹
用戶情感檢測是很多情感相關應用的基礎和核心。在本文中,我們提出一種集成詞語義特征、多元詞組語義特征和句子級語義特征的情感分類模型,用於識別智能客服係統用戶對話中包含的“著急”、“氣憤”和“感謝”等情感。關於不同層次語義特征的抽取技術,相關工作中已經多有提及,我們將不同層次的語義特征結合到一起,能夠有效提升最終的情緒識別效果。圖 2 給出了該情感分類模型的架構圖。
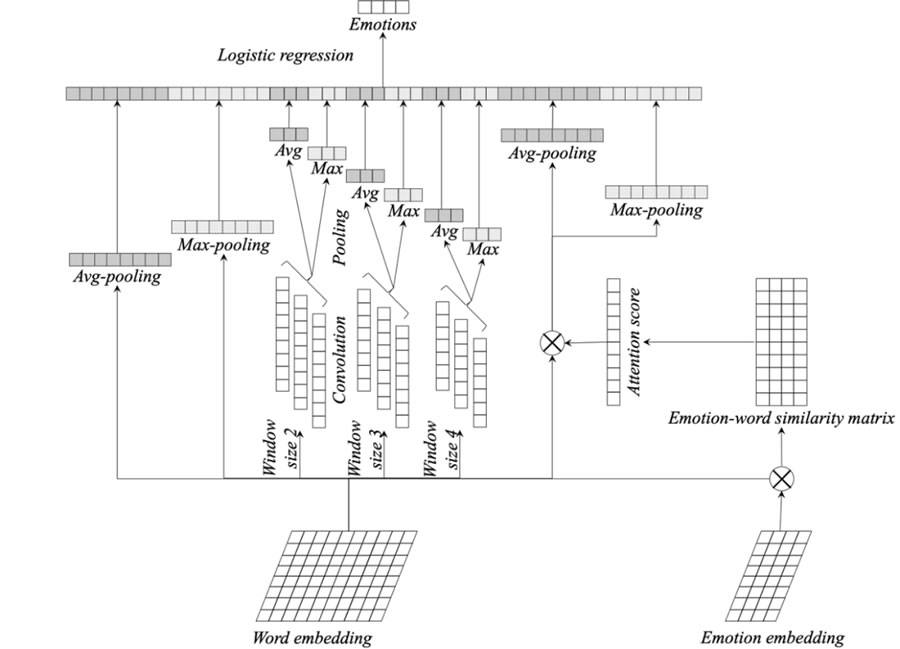
圖 2:智能客服係統中的用戶情感檢測模型
2 句子級語義特征抽取
Shen 等人[3]提出 SWEM 模型,該模型將簡單的池化策略應用於詞嵌入向量,實現句子級別的語義特征抽取,並且基於此類特征進行訓練得到的分類模型和文本匹配模型能夠得到與經典的卷積神經網絡類模型和循環神經網絡類模型幾乎持平的實驗效果。
在我們的模型中,我們利用 SWEM 模型的特征抽取能力,獲取用戶問題的句子級別語義特征,並將其用於對用戶問題的情感分類模型中。
3 多元詞組語義特征抽取
傳統的 CNN 模型在很多情況下被用於抽取 n 元詞組語義特征,其中 n 是一個變量,表示卷積窗口大小。在本文中,我們根據經驗將 n 分別設置為 2、3 和 4,並且針對每一種窗口大小,我們分別設置 16個 卷積核,以用於從原始的詞向量矩陣中抽取豐富的 n 元詞組語義信息。
4 詞級別語義特征抽取
我們利用 LEAM 模型 [1] 抽取詞級別的語義特征。LEAM 模型同時將詞語和類別標簽進行同維度語義空間的嵌入式表示,並且基於該表示進行文本分類任務的實現。LEAM 利用類別標簽的表示,增加了詞語和標簽之間的語義交互,以此達到對詞級別語義信息更深層次的考慮。圖 3(2)中給出了類別標簽和詞語之間的語義交互的圖示,並且給出了 LEAM 模型與傳統模型之間的對比。
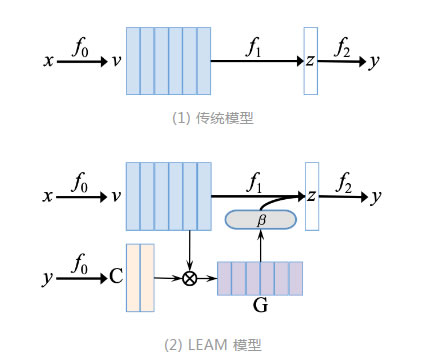
圖 3:LEAM模型中詞語和類別標簽之間的語義交互(傳統方法和LEAM模型的對比)
最後,不同級別的語義特征會在被合並在一起之後,輸入到整個模型的最後一層,由邏輯回歸模型進行最終的分類訓練。
表 1 中給出了我們提出的集成式模型和三個隻考慮單個層次特征的對比模型之間的線上真實評測效果對比結果。

表 1:集成模型和三種 baseline 模型的效果對比
三 用戶情感安撫
1 用戶情緒安撫整體框架介紹
本文中提出的用戶情緒安撫框架包括離線部分和在線部分,如圖 4 所示。
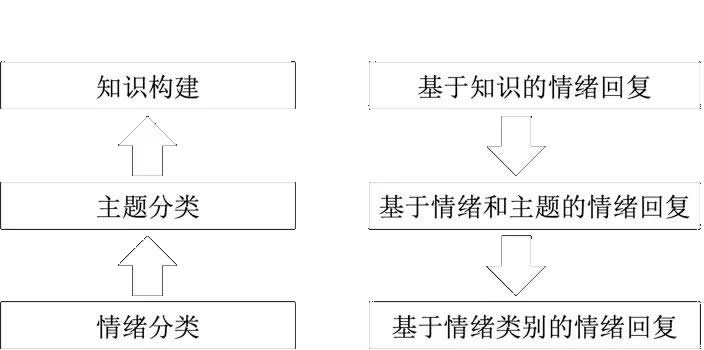
圖 4:用戶情緒安撫整體框架
離線部分
首先需要對用戶的情緒進行識別。此處我們選取了需要安撫的用戶常見的七種情緒進行識別,它們是害怕、辱罵、失望、委屈、著急、氣憤和感謝。
其次,我們對用戶問題中包含的主題內容進行識別,此處由專門的業務專家總結了用戶常見的 35 種主題表達內容,包括“抱怨服務質量”和“反饋物流太慢”等。主題識別模型,我們使用與情緒識別同樣的分類模型設計。
知識構建是針對一些用戶表達內容更具體的情況,整理其中高頻出現的並且需要進行安撫的用戶問題。這些具體的用戶問題之所以沒有合並到上述的主題維度進行統一處理,是因為主題維度的處理還是相對粗粒度一些,我們希望針對這些高頻的更聚焦的問題,同樣進行更聚焦的安撫回複,實現更好的回複效果。
針對情緒維度、“情緒 + 主題”維度和高頻用戶問題維度,業務專家分別整理了不同粒度的安撫回複話術。特別地,在高頻用戶問題維度,我們將每一個“問題 - 回複”搭配稱為一條知識。
在線部分
基於知識的安撫是針對帶有具體情緒內容表達的用戶進行安撫,在此我們使用了一種文本匹配模型來評價用戶問題與我們整理好的知識中的問題的匹配度。如果在我們整理好的知識中存在與當前用戶輸入問題意思非常相近的問題,則對應的回複直接返回給用戶。
基於情緒和主題的情感回複,是指同時考慮用戶表達內容中包含的情緒和主題信息,給予用戶合適的情感回複。相比於基於知識的安撫,此種方式的回複會更加的泛化一些。
基於情緒類別的情感回複,是隻考慮用戶表達內容中的情緒因素而對用戶進行相應的安撫回複。此回複方式是上述兩種回複方式的補充和兜底,同時回複的內容也會更加的通用。

圖 5:用戶情緒安撫示例
圖 5 給出了在線情感安撫的三個示例,分別對應上述的三種不同層麵的回複機製。 表 2:需要安撫的情感分類效果對比
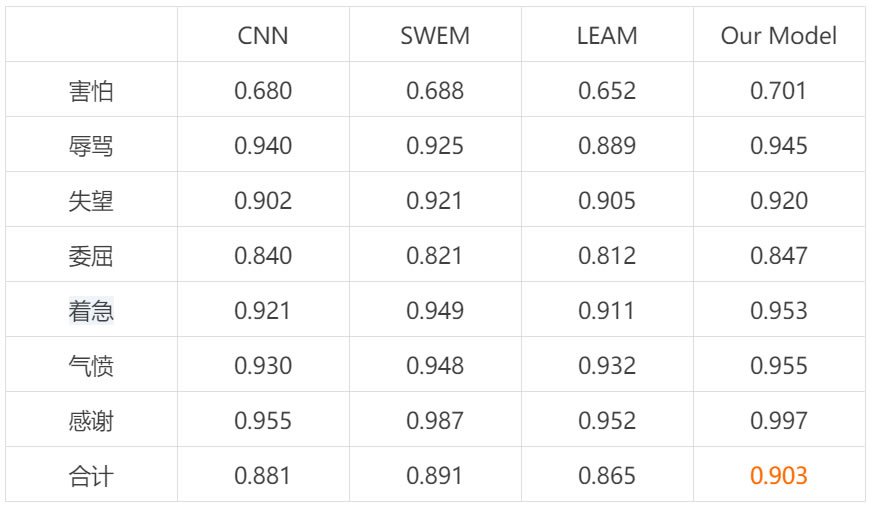
表 2 給出了針對需要安撫情感的分類模型效果對比,包括每種情感類別的單獨效果以及最終的整體效果。表 3 給出了針對主題的分類模型效果對比。表4給出了針對幾種負麵情感,增加了情緒安撫之後,用戶滿意度的提升效果。表 5 給出了針對感激這種情感,增加了情緒安撫之後,用戶滿意度的提升效果。 表 3:主題分類效果對比 表 4:負麵情緒安撫對用戶滿意度的效果對比 表 5:感激情感安撫對用戶滿意度的效果對比
四 情感生成式語聊
1 情感生成式語聊模型
圖 6 中給出了智能客服係統中的情感生成式語聊的模型圖。圖中,source RNN 起到了編碼器的作用,將源序列s映射為一個中間語義向量 C,而 target RNN 作為解碼器,則能夠根據語義編碼 C 以及我們設定的情緒表示 E 和主題表示 T,解碼得到目標序列 y。此處的 s 和 y,分別對應圖中由詞語序列組成的“今天心情很好”和“好開心呀!”兩個句子。
通常,為了使解碼器能夠保留來自編碼器的信息,編碼器的最後一個狀態將作為初始狀態傳遞給解碼器。同時,編碼器和解碼器往往使用不同的 RNN 網絡用以捕獲問句和回複句不同的表達模式。具體的計算公式如下:
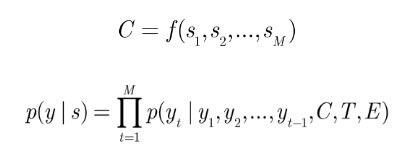
雖然基於 Seq2Seq 的對話生成模型取得了不錯的效果,但是在實際應用中模型很容易生成安全但是無意義的回複。原因在於該模型中的解碼器僅僅接收到編碼器最後的一個狀態輸出 C,這種機製對處理長期依賴效果不佳,因為解碼器的狀態記憶隨著新詞的不斷生成會逐漸減弱甚至丟失源序列的信息。緩解這個問題的一個有效方式是引入注意力機製[2]。
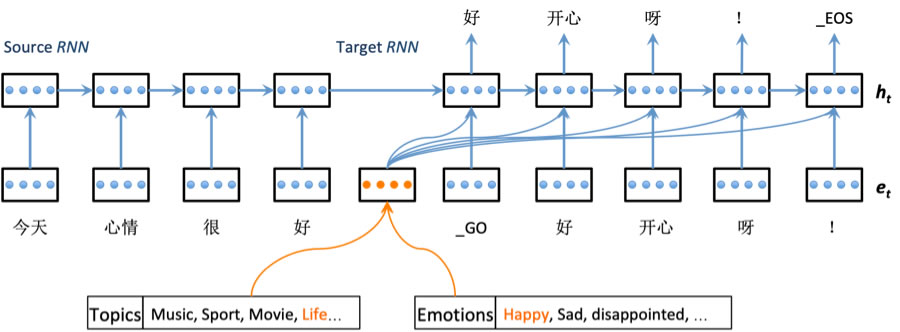
圖 6:智能客服係統中的情感生成式語聊模型

2 情感生成式語聊模型結果
模型訓練完成之後,在真實的用戶問題上進行測試,結果由業務專家進行檢查,最終的答案合格率約為 72%。另外,回複文本的平均長度為 8.8 個字,非常符合阿裏小蜜語聊場景中對回複長度的需求。表 6 中給出了本文模型 AET(Attention-based emotional & topical Seq2Seq model)與傳統 Seq2Seq 模型的效果對比。對比主要集中在內容合格率以及回複長度兩個方麵。添加了情緒信息之後,回複內容較之傳統 seq2seq 模型會更為豐富,而符合用研分析的“5 - 20字”最佳機器人語聊回複長度的內容占比也會大幅增加,最終使得整體的回複合格率提升明顯。
圖 7 中給出了阿裏小蜜情緒生成式語聊模型在小蜜空間中的應用示例。圖中兩個答案均由情緒生成式模型給出,並且,對於用戶辱罵機器人太傻的用戶輸入,我們的模型可以根據設置的對應合理的話題和情緒,產生不同的答案,豐富了答案的多樣性,圖中兩個答案,則是由‘委屈’和‘抱歉’兩個情緒產生。 圖 7:小蜜空間中的情緒生成式語聊應用實例
五 客服服務質檢
1 客服服務質量問題定義
本文所說的客服服務質檢是針對人工客服在和客戶對話的過程中可能出現的存在問題的服務內容進行檢測,從而更好地發現客服人員在服務過程中存在的問題並協助客服人員進行改進,達到提高客服服務質量,最終提高客戶滿意度效果。據作者所知,目前還沒有公開實現的針對客服係統中客服服務質量檢測的人工智能相關算法模型。
與人機對話不同,人工客服和客戶的對話並不是一問一答形式,而是客戶和客服分別能夠連續輸入多句文本。我們的目標是檢測每一句客服的話術內容是否包含“消極”或者“態度差”兩種服務質量問題。
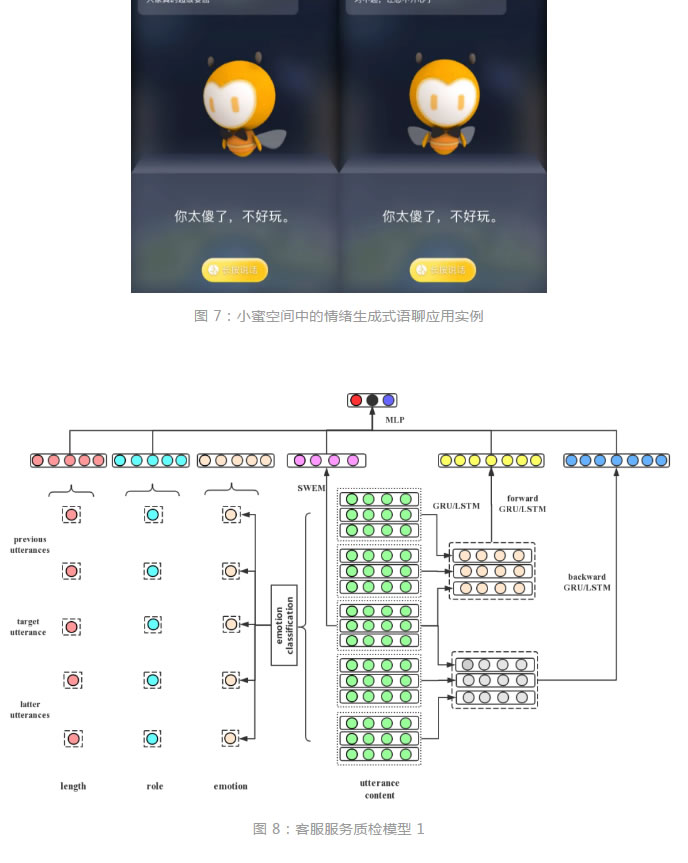
2 客服服務質檢模型
為了檢測一句客戶話術的服務質量,我們需要考慮其上下文內容,包括用戶問題和客服話術。我們考慮的特征包括文本長度、說話人角色和文本內容。其中,針對文本內容,除了利用 SWEM 模型對待檢測的當前客服話術進行特征抽取,我們還對上下文中的每輪話術進行情緒檢測,發現用戶情緒類別和客服情緒類別作為模型特征,而此處使用的情緒識別模型也如第 2 章中所述一致,亦不再贅述。此外,我們還考慮了兩種結構(圖 8 中模型 1 和圖 9 中模型 2)對基於上下文內容的文本序列語義特征進行抽取。
其中,模型 1 在對當前客服話術及其上下文每句文本進行基於 GRU 或 LSTM 的編碼之後,針對編碼結果,考慮利用正向和反向 GRU 或者 LSTM 分別對當前待檢測客服話術的上文和下文的編碼結果進行再次的序列化編碼,如此得到的兩個序列化編碼結果均是以當前話術為尾句,能夠更好的體現當前話術的語義信息。模型結構如圖 8 所示。
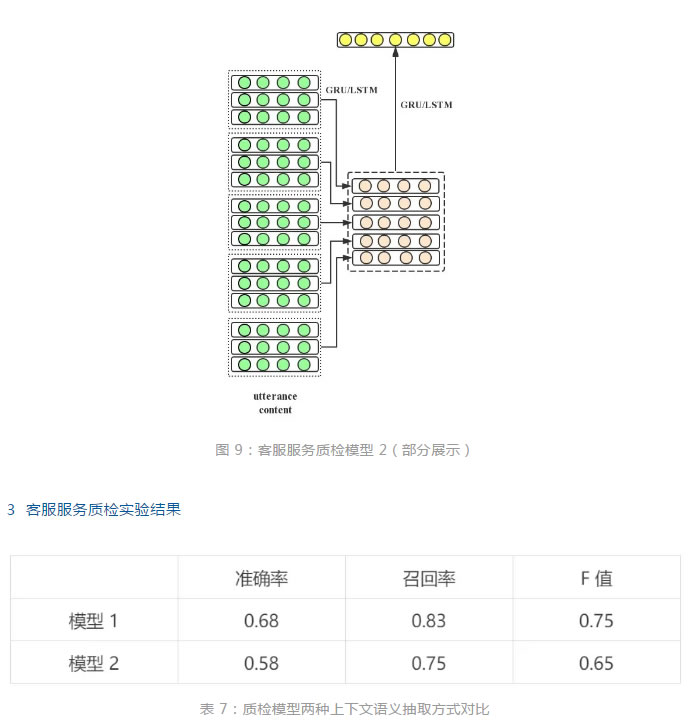
另外,模型 2 將當前客服話術及其上下文的編碼結果,再次按照前後順序進行整體的正向 GRU 或 LSTM 編碼作為最終的語義特征。模型結構的部分展示如圖 9 所示。模型 1 與模型 2 相比,模型1會更加凸顯當前待檢測話術的語義信息,而模型 2 則更加多得體現整體上下文的序列化語義信息。
我們比較兩種上下文語義信息抽取模型的效果,表7中給出了對比結果,結果顯示模型 1 的效果要優於模型 2,可見對於當前待檢測話術的語義信息確實需要給予更多的權重,而上下文的語義信息可以起到輔助識別的作用。此外,之前提到的 GRU 或者 LSTM 兩種方法在實際的模型訓練過程中,效果差別不大,但是 GRU 方法要比 LSTM 方法在速度上更快一些,因此所有的模型實驗過程中均使用了 GRU 方法。
此外,區別於模型層麵的指標分析,我們針對模型在實際的係統層麵的指標也進行了相應的分析,包括了質檢效率以及召回率兩個維度。這兩個指標,我們是以模型的結果與之前純人工質檢的結果進行對比得到。如表 8 中所示,不管是質檢效率還是質檢的召回率都得到了非常大的提升。其中,人工質檢的召回率比較低的原因,是因為人工不可能檢測所有的客服服務記錄。 表 8:實際係統層麵的模型指標評價結果
六 會話滿意度預估
1 會話滿意度
目前在智能客服係統的性能評估指標中,有一項最為重要的指標為用戶會話滿意度。而針對智能客服係統中的用戶會話滿意度自動預估的工作,據作者所知還沒有相關的研究成果。
針對智能客服係統中的會話滿意度預估場景,我們提出了會話滿意度分析模型,可以更好的反應當前用戶對智能客服的滿意度程度。由於不同用戶存在評價標準差異,會存在大量會話內容、會話答案來源、會話情緒信息完全相同的情況下情緒類別不一致的情況。因此我們采用了兩種模型訓練方式:第一種是訓練模型擬合情緒類別(滿意、一般、不滿意)的分類模型,另一種是訓練模型擬合會話情緒分布的回歸模型,最後對兩種方式效果做了對比。
2 會話滿意度特征選取
會話滿意度模型考慮了各種維度信息:語義信息(用戶話術)、情緒信息(通過情感檢測模型獲取)、答案來源信息(回複當前話術的答案來源)。
語義信息是用戶與智能客服交流過程中所表達的內容信息,它可以從用戶話術中較好反應用戶當前滿意狀況。我們在模型中使用的語義信息是指會話中的多輪話術信息,在模型處理過程中,為了保證每次模型能夠處理相同輪次的話術,我們實驗中隻使用會話中最後4句用戶話術,選擇此種方式的原因是通過會話數據分析,用戶在會話即將結束時的語義信息與整體會話滿意程度更為相關。比如,用戶在會話結尾時表達感激之類的話術基本表示滿意,而表達批評之類的話術則很可能表示了對服務的不滿。
情緒信息一般在用戶滿意度方麵起著非常大的參考作用,當用戶出現憤怒、辱罵等極端情緒時,用戶反饋不滿意的概率會極大。此處的情緒信息與語義信息中的話術一一對應,對選取的幾輪話術分別進行情緒識別,獲取對應的情緒類別信息。
答案來源信息可以很好的反應用戶遇到何種問題,由於不同的答案來源代表著不同業務場景,不同場景問題產生的用戶滿意度狀況差異性比較明顯。比如,投訴、維權類會比谘詢類更容易導致用戶不滿意。
3 會話滿意度模型
在本文中,我們提出了結合語義信息特征、情緒信息特征和答案來源信息特征的會話滿意度預估模型。模型充分考慮了會話中的語義信息,並且使用了數據壓縮的方式將情緒信息和答案來源信息進行了充分表達。模型結構如圖 10 所示。
語義特征抽取。語義信息抽取方式使用層次 GRU/LSTM,第一層獲取每句話的句子表示(圖 10 中 first layer GRU/LSTM 部分),第二層根據第一層句子表示結果獲得多輪用戶話術的高階表示。
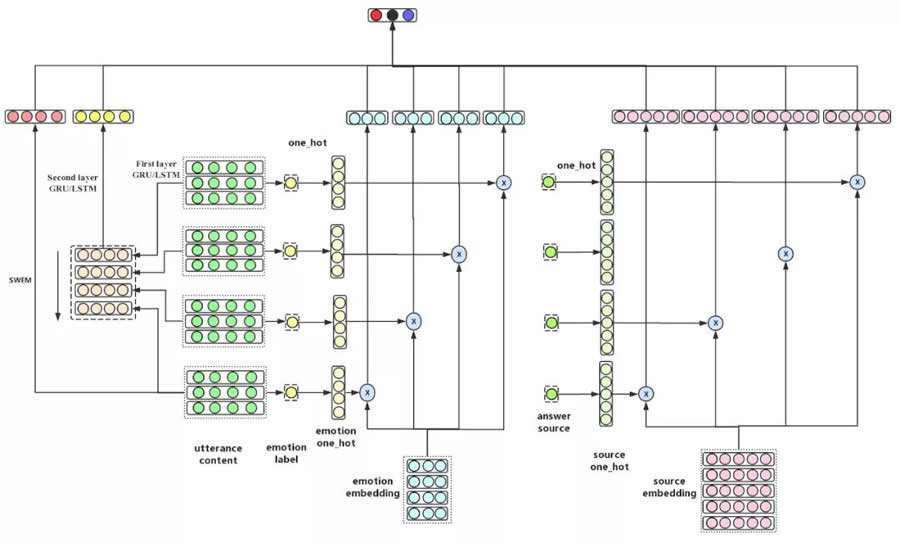
圖 10:智能客服係統中的用戶會話滿意度預估模型
(圖 10 中 second layer GRU/LSTM 部分),此處充分利用了用戶話術的序列信息。除此之外,還將獲取最後一句話的 SWEM 句子特征,以增強最後一句話術語義特征的影響。
情緒特征抽取:由於獲取的情緒特征是 one-hot 類型,而 one-hot 缺點比較明顯,數據稀疏且無法表示情緒間直接關係。此處我們學習一個情緒 embedding,來更好的表達情緒特征。
答案來源特征抽取:初始答案來源特征同樣為 one-hot 特征,但由於答案的來源有 50多種,導致數據非常稀疏,因此需要進行特征壓縮,此處同樣使用了 embedding 學習方式,來表示答案來源特征。
模型預測層:分別嚐試了滿意度類別預測和滿意度分布預測,前者預測屬於分類模型,後者屬於回歸模型。
4 會話滿意度預估實驗結果 圖 11:用戶會話滿意度預估結果比較
實驗結果如圖 11 中所示。從實驗結果來看分類模型滿意度預估效果較差,平均比實際用戶反饋高了 4 個百分點以上,回歸模型可以很好的擬合用戶反饋結果,而且減小了小樣本結果的震蕩,符合預期。如表 9 中所示,回歸模型的均值與用戶真實反饋的結果的差值僅為 0.007,而方差則比之前減小了三分之一,證明了回歸模型的有效性。 表 9:用戶會話滿意度預估結果比較
七 總結
本文總結了目前智能客服係統中情感分析能力的一些實際應用場景以及相應的模型介紹和效果展示。雖然情感分析能力已經滲透到了智能客服係統人機對話過程的各個環節中,但是目前也隻能算是一個良好嚐試的開始,其在智能客服係統的類人能力構建進程中還需要發揮更大的作用。
 |
| 機器人招商Disinfection Robot機器人公司機器人應用智能醫療物聯網機器人排名機器人企業機器人政策教育機器人迎賓機器人機器人開發獨角獸消毒機器人品牌消毒機器人合理用藥地圖 |


